


Table of contents
When we work on a streaming project, an important question to consider is the choice of the streaming platform. Many solutions can be evaluated as shown in my last article.
The Data analysis in the streaming project is not stationary as data is continuously coming and refreshing the last result. Different sources and output are used while working on streaming Data and 3 major parts have to be considered:
- The input Data: Kafka, HDFS, AWS S3…
- The streaming engine: Spark Structured Streaming…
- The output: HDFS, Databases…
Our goal
In the perspective of achieving the project of sentiment analysis using tweets, It is important to understand all the elements that are in our architecture. Apache Spark is the most commonly used among the streaming platform because of its performance and the native language (Python, Scala, Java and SQL) that it supports. In this article, we will get to know Apache Spark Structured Streaming.
Overview
Spark Structured Streaming is scalable and a fault-tolerant stream processing engine. It is built on Spark SQL Engine and processes real-time streaming data in the spark ecosystem. Spark Structured Streaming uses Dataframes and Datasets APIs with Python, Scala, Java, and R. It also provided event-time windows to process data. Structured Streaming queries are processed with two-stream execution engines:
- Micro batch execution for micro-batch stream processing
- Continuous Execution for continuous stream execution
Output modes
After processing of Data, we have to store the output somewhere as mentioned at the beginning of this article. It is important to notice that received data is appended to a continuously flowing of data. Various output modes are available:
- Append mode: here, only newly rows will be output
- Update mode: update rows will be output
- Complete mode: In this mode, all the rows processed will be output
Let's code
This part will present the first part of a streaming project using Twitter data. Only the part with Spark structured streaming will be discussed. Here, Spark will receive data from Kafka and will process it and output the result.
Import libraries
Import the required libraries:
from pyspark.sql import functions as F
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.types import StringType, StructType, StructField
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
Create Spark session
We create now a Spark session.
spark = SparkSession.builder.appName("TwitterSentimentAnalysis").config("spark.jars.packages",
"org.apache.spark:spark-sql-kafka-0-10_2"
".12:3.1.2").getOrCreate()
Create streaming DataFrame Create a streaming Dataframe. The format here is Kafka.
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "twitter") \
.load()
Transformation In this little part of code, when we run,
df.selectExpr("CAST(value AS STRING)")
we get only the value/output received from Kafka and not all other components (timestamp…) add by Spark in each row. So, this Element received by Kafka is JSON. And the part that interests us is "text". That is the exact tweet.
mySchema = StructType([StructField("text", StringType(), True)])
values = df.select(from_json(df.value.cast("string"), mySchema).alias("tweet"))
df1 = values.select("tweet.*")
Output As we can see, the output mode is "append" so the newly processed row will be output.
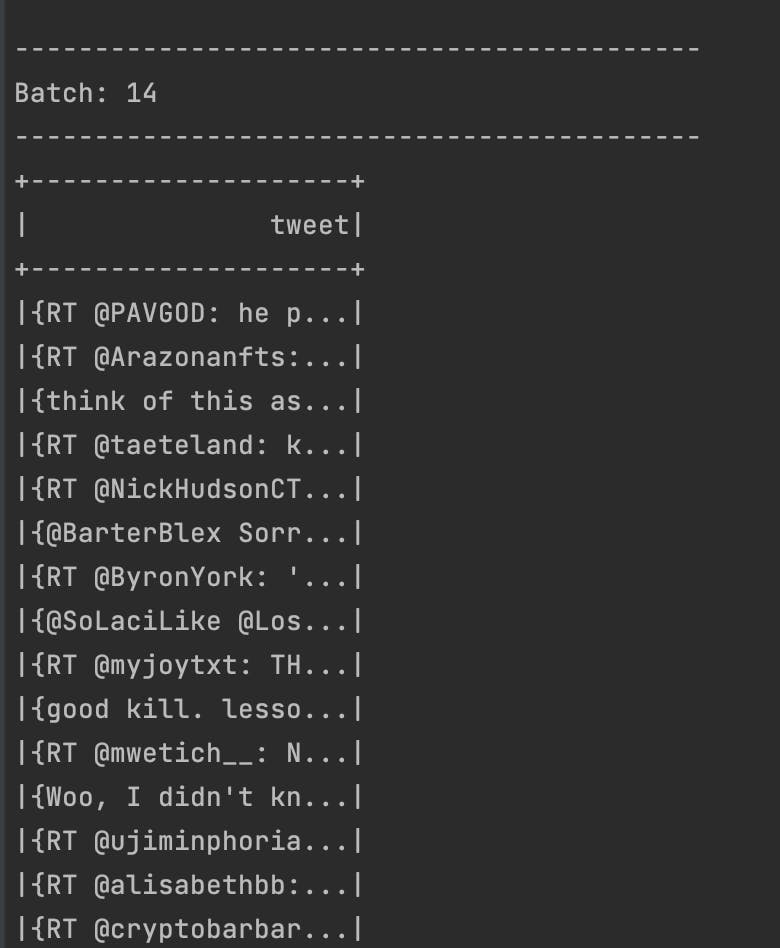
We have successfully written our first spark streaming application! The entire project is available on my Github.
I hope this information was helpful and interesting, if you have any questions, or you just want to say hi, I'm happy to connect and respond to any questions you may have about my blogs! Feel free to visit my website for more!