


According to Wikipedia, Apache Spark is an open-source unified analytics engine for large-scale data processing.
A big decision for Big Data leaners or Data engineers is to choose the language for data processing. Fortunately, Spark provides development API for Scala, Python and Java and R. Beyond all these APIs, Python and Scala are the most popular. Frequently, we hear questions like: Should I use Python, Scala? What are the pros and cons of each programming language? In which case is Python or Scala the more important one to use?
Our goal
Now working on a project of streaming data, it is important to choose the good tools in order to accomplish the project. The first question after ingesting Data is how to process those Data? One answer is by using Spark but Spark has multiple API's. Then, which one is appropriate for our case.
The purpose of this article is to bring some answers to these questions. The comparison of these languages in spark can be seen into multiple spectrums: performance, community, learning curve, platform, application to Data Science and Machine Learning.
Before we go deep in the comparison, it is important to define those two languages: Python and Scala.
What is Scala?
Scala is an acronym for "scalable language". It is a combined functional programming and object-oriented programming language which was designed by Martin Odersky in 2004. Scala runs in JVM (Java Virtual Machine). Programmers find Scala code compared to other languages simple to use for writing, compiling, debugging.
What is Python?
Python is an interpreted, object-oriented, high-level programming language. Python programmers like python because it is relatively simple, it supports multiple packages and modules. Also, its interpreter and standard libraries are available for free.
Performance
We often hear that Scala is 10X faster than Spark. We will verify this by doing a test on the word count project. Notice that a word count project is a hello world project in the Big Data ecosystem. To realize this project, I download a text file of 934.57 MB.
Python Spark Word Count
import time
from pyspark.sql import SparkSession
start_time = time.time()
# Create SparkSession and sparkcontext
spark = SparkSession.builder.appName("wordcount").config("spark.jars.packages",
"org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2").getOrCreate()
sc = spark.sparkContext
# Read the input file and Calculating words count
text_file = sc.textFile(r"/Users/lorenapersonel/PycharmProjects/SparkWordCount/data/words_to_count.txt")
"""
- flatMap is needed here to return every word (separated by a space) in the line as an Array
- map each word to a value of 1 so they can be summed
- get an RDD of the count of every unique word by aggregating (adding up) all the 1's you wrote in the last step
"""
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
.sortBy(lambda a: a[1], ascending=False)
counts.saveAsTextFile(r"/Users/lorenapersonel/PycharmProjects/SparkWordCount/data/output_python")
print("Elapsed Time in mili seconds: ", (time.time() - start_time) * 1000)
This is a simple code that counts the number of occurrences of words in the text file and writes the result in another file. We obtain a result as shown in the image above:
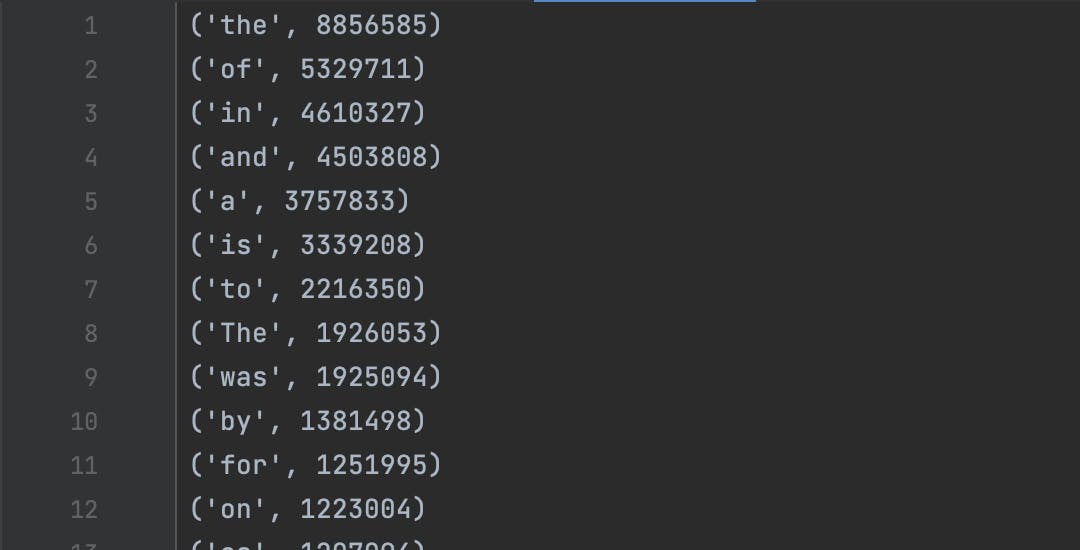
The execution time of this program is 57245.10478973389 ms = 57,245000000000004547s
Elapsed Time in milliseconds: 57245.10478973389 ms ~ 57245ms
Scala Spark Word Count
package demo
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object wordcount {
def main(args: Array[String]): Unit = {
val start1: Long = System.currentTimeMillis
val conf: SparkConf = new SparkConf().setAppName("Spark Performance Word Count").setMaster("local[*]")
val sc = new SparkContext(conf)
val text_file: RDD[String] = sc.textFile("/Users/lorenapersonel/Documents/scalaProject/data/words_to_count.txt")
val count: RDD[(String, Int)] = text_file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_+_)
.sortBy(_._2)
count.saveAsTextFile("/Users/lorenapersonel/Documents/scalaProject/data/output_scala")
val end1: Long = System.currentTimeMillis
System.out.println("Elapsed Time in mili seconds: " + (end1 - start1))
}
}
We get the execution time of 27719 ms = 27,719 s.
Elapsed Time in milliseconds: 27719 ms
In this case, we have a ratio of 57245/27719= 2.06. From this, we can say that Scala is faster than Python but it's not always 10x faster.
Community
I used to work we Python and I find that when I have a problem I can get to the community to help me solve the problem. Python community continues to contribute by extending its abilities and helping others get into it. The community hosts webinars, code competitions, conferences etc. I think that Python has a huge community compared to Scala.
Learning Curve
Python and Scala are object-oriented programming languages. As a beginner, I find Scala complex. I also find that some features resemble Java. On the other hand, Python is easy to get started for beginners. It has intuitive logic and comprehensive libraries.
Platform
Scala is available for all platforms that are supported by JVM. it's based on JVM, so its source code is compiled to Java bytecode before being executed by JVM. Python needs the Python interpreter to run the program.
Application to Machine learning and Data Science
Scala is the main language used to write distributed Big Data processing and transformation. On the other hand, Python is the preferred language among Data scientists and people working on machine learning. Python has a library that is compatible with Spark.
Scalability
Talking about scalability, we can say that, Python is more suitable for small/middle scale projects. Scala is suitable for projects of a big scale.
Conclusion
To conclude, each programming language has its pros and cons. So, deciding between Python or Scala depend on the project you are working on. Scala offers great performance and it's faster than python as we have seen in the example above. Before choosing the best programming language with Apache Spark, it's important to learn both and get your own opinion. As a Scala's beginner myself, I will take time to improve my skills and in the meantime, I will use python with Apache Spark on my projects.
I hope this information was helpful and interesting, if you have any questions, or you just want to say hi, I'm happy to connect and respond to any questions you may have about my blogs! Feel free to visit my website for more!