
Sentiment analysis on streaming Twitter data using Kafka, Spark Structured Streaming & Python (Part 1)


This project is a good starting point for those who have little or no experience with Kafka & Apache Spark Streaming. Last time, we did data ingestion of Twitter Data using Kafka. It is important to notice that those data ingest using Kafka has to be explored. This can be possible using Machine learning, Deep Learning or other types of possible analysis on Data.
This article will just show a simple sentiment analysis on Twitter data using Spark.
Architecture
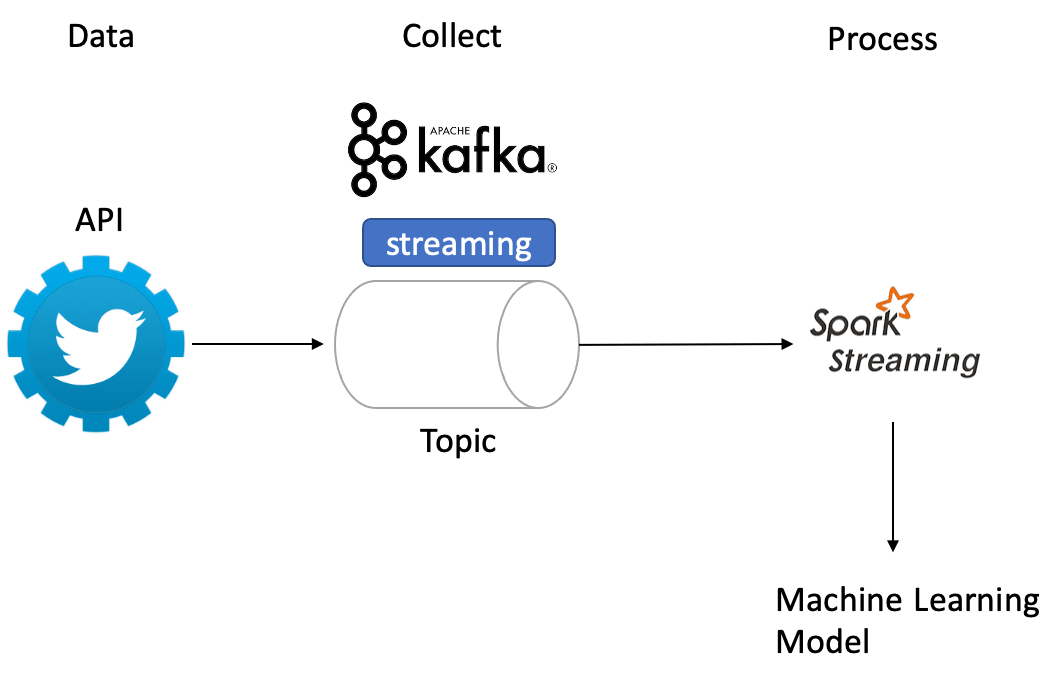
Input data: Live tweets with a keyword Main model: Data preprocessing and applying sentiment analysis on the tweets Output: Text with all the tweets and their sentiment analysis scores (polarity and subjectivity)
We use Python version 3.7.9 and Spark version 3.2.1 and Kafka 3.1.0.
Libraries
tweepy: interact with the Twitter Streaming API and create a live data streaming pipeline with Twitter pyspark: preprocess the twitter data (Python’s Spark library) textblob: apply sentiment analysis on the twitter text data
Part 1: Ingest Data using Kafka
This part is about sending tweets from Twitter API. To do this, follow the instructions in my last article about the ingestion of Data using Kafka. Here is the link.
Part 2: Tweet preprocessing and sentiment analysis
In this part, we receive tweets from Kafka and preprocess them with the pyspark library which is python's API for spark. We then apply sentiment analysis using textblob; A python's library for processing textual Data. I wrote an article on sentiment analysis sentiment analysis . I used the same code in this project.
After sentiment analysis, we write the sentiment analysis scores in the console. We have also the possibility to store in a parquet file, which is a data storage format. The entire project is available here
Conclusion
To conclude, this is the first part of a project whose other parts will be discovered later.
Images references: