


Kafka was first developed by LinkedIn while LinkedIn wanted to tracks the users' activity (page views, messages, etc...) in the platform. Later, the application was given to Apache as an Open Source project to which it belongs nowadays. Before jumping into Kafka it's important and much easier to explain the key concepts that gravitate towards it.
Kafka Key concepts
Publish/subscribe
In order to explain and understand this concept, we will start with an analogy: Let's suppose that I am writing this article and I wanted to send it to you (in particular). This could only be possible if maybe I have your email address or another way to contact you.
But with Hashnode, as a blogger, I can write my article and publish it and you can come to the platform and pick my article or other articles of your interest. Hashnode can be then considered as a distributed platform that allows a creator(Producer) to publish articles and readers(Consumer) subscribe and read the content based on its interest. This type of system helps different consumers to access the same information and different producers to produce content clearly, all this without the two being aware of each other.
As you can see in the following image, we have a scalable architecture where everyone can access the information they are interested in.
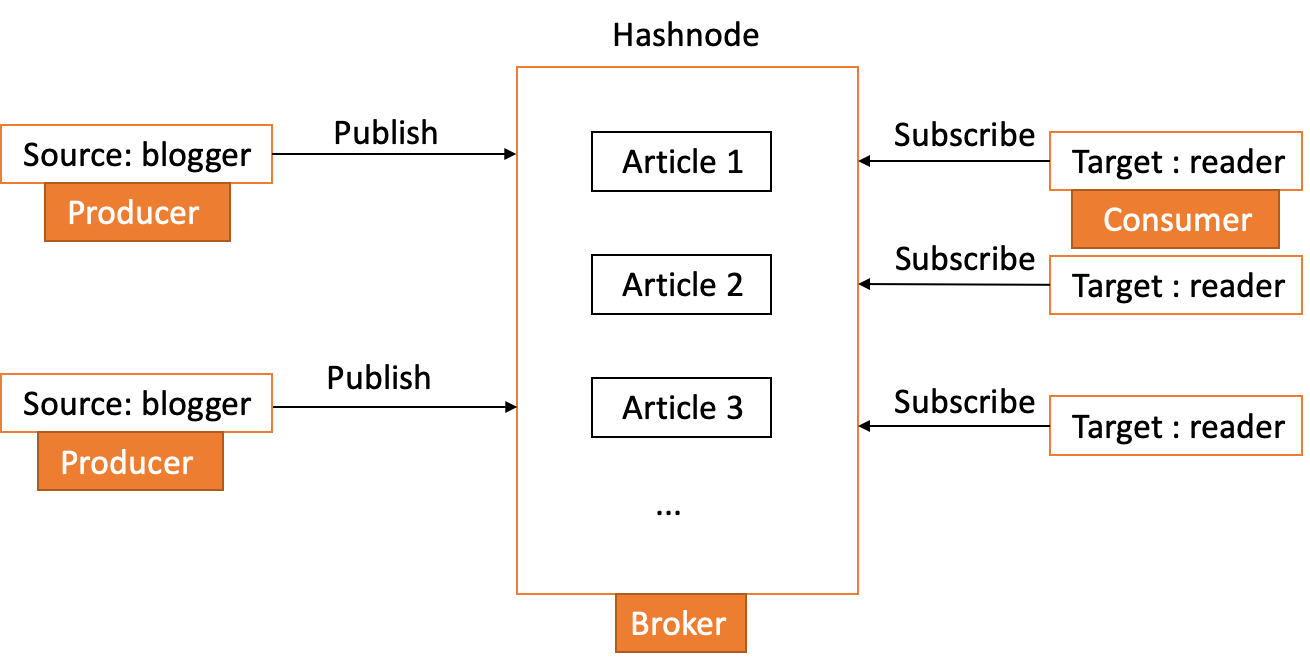
The Publish/Subscribe concept is the backbone of Kafka.
From this, we can conclude that:
- A Broker is a Kafka server.
- A Producer is a system that sends information to Kafka.
- A Consumer is a system that reads the information in Kafka.
Event-based
An analogy will be the best way to understand this. Let's suppose that we have a web portal. When a client buys a product, information is stored in a database. If we want to query the system and ask for the consumer x who bought the product Y in-store Z at W time, this will implicate querying that will involve other tables which are part of all systems. And if this system continues to grow and adds more tables and more one to one connections, it will become complex and reduce the performance of the application.
On the other hand in the event-based approach, the web portal will send events to the queue. This event will pack all the information (This could be all the information about a purchase: client name, time of purchase, products...). Then the event is then exploited by another system that is completely dislocated from the web portal.
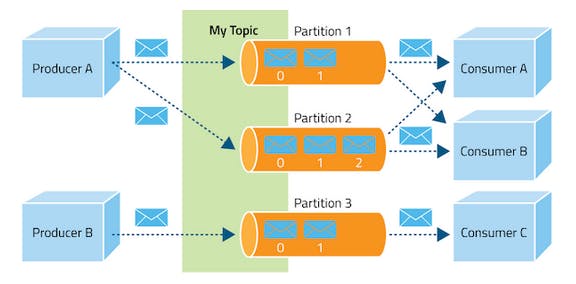
Message - Topic - Partition
A Message is sent by a Producer and received by a Consumer. The message is stored in a Topic. If for example, a Topic is customer, then all the messages qualified as Customer will be stored in the Topic. A Partition is one subset of a Topic. A topic can have multiple partitions.
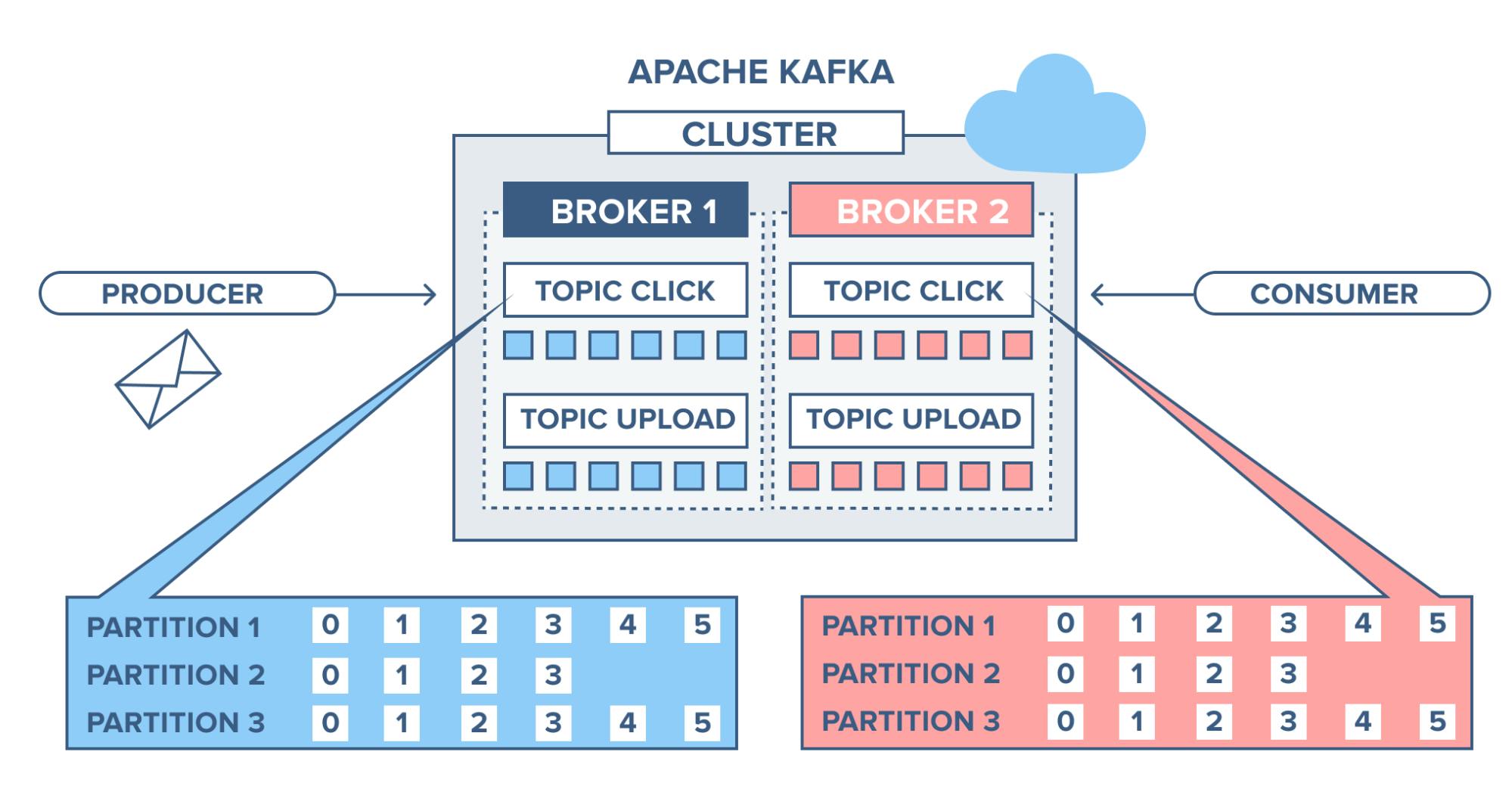
Kafka cluster - Kafka server
In this image, we see one Kafka Cluster with two Kafka Server. A Kafka Server is a Broker. A Broker is constituted of one or multiple Topics. And, a Kafka Cluster has one or multiple Broker.
Let's Code
Architecture
The advantage of using Kafka with Twitter Stream is fault tolerance. We have a first module The Producer which collect data from Twitter, then saves it, and another module The Consumer which reads the logs and then processes the Data. The Producer just saved the data as logs into the queue and the consumer is responsible for reading those logs and processing them. Below the architecture:

Getting started
As you know, to stream data from Twitter you need a Twitter developer account. Below is a list of things you will need to get started :
- Twitter developer account and your credentials
- Intermediate level Python knowledge and familiarity with JSON
- Familiarity with the Twitter API and the Tweepy Python Library
Setting up and running
To install Kafka, you have to download binaries and run it. Kafka is based on JVM languages like scala and Java, you must install or use Java 7 or greater.
For Mac OS there is an excellent guide by Maheshwar Ligade, and they definitely exist for other OS’s as well.
Step 1: Setting Up Zookeeper and start the Kafka environment
Once the download is complete you will need to set up the Zookeeper Server.
cd kafka_2.13-3.1.0
bin/zookeeper-server-start.sh config/zookeeper.properties
Open another terminal session and run:
bin/kafka-server-start.sh config/server.properties
Once all services have successfully launched, you will have a basic Kafka environment running and ready to use.
Step 2: Create the topic to store the events
Before you can write your first events, you must create a topic. Open another terminal session and run:
bin/kafka-topics.sh --create --topic twitter --bootstrap-server localhost:9092
The kafka-topics.sh command display information. It gives details about the partition count... as you can see in the image above.
bin/kafka-topics.sh --describe --topic twitter --bootstrap-server localhost:9092

Step 4: Python Code
Installing Kafka API for Python
So before we get started using Kafka in Python, we will need to install the Kafka library in Python. On your IDE, create a virtual environment and install the library.
pip install kafka-python
Producer code
On your IDE, create a new Python module called producer. you can use Tweepy's on function with the KafkaProducer to send the raw Twitter into your Kafka Producer.
Here you can use your Tweepy’s on_data function with the KafkaProducer to feed the raw Twitter data into your Kafka Cluster.
import tweepy
from kafka import KafkaProducer
import logging
"""API ACCESS KEYS"""
consumerKey = "XXX"
consumerSecret = "XXX"
accessToken = "XXX"
accessTokenSecret = "XXX"
producer = KafkaProducer(bootstrap_servers='localhost:9092')
search_term = 'Bitcoin'
topic_name = 'twitter'
def twitterAuth():
# create the authentication object
authenticate = tweepy.OAuthHandler(consumerKey, consumerSecret)
# set the access token and the access token secret
authenticate.set_access_token(accessToken, accessTokenSecret)
# create the API object
api = tweepy.API(authenticate, wait_on_rate_limit=True)
return api
class TweetListener(tweepy.Stream):
def on_data(self, raw_data):
logging.info(raw_data)
producer.send(topic_name, value=raw_data)
return True
def on_error(self, status_code):
if status_code == 420:
# returning False in on_data disconnects the stream
return False
def start_streaming_tweets(self, search_term):
self.filter(track=search_term, stall_warnings=True, languages=["en"])
if __name__ == '__main__':
twitter_stream = TweetListener(consumerKey, consumerSecret, accessToken, accessTokenSecret)
twitter_stream.start_streaming_tweets(search_term)
Consumer code
This module will read the raw data from Kafka Cluster.
from kafka import KafkaConsumer
import json
topic_name = 'twitter'
consumer = KafkaConsumer(
topic_name,
bootstrap_servers=['localhost:9092'],
auto_offset_reset='latest',
enable_auto_commit=True,
auto_commit_interval_ms=5000,
fetch_max_bytes=128,
max_poll_records=100,
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
tweets = json.loads(json.dumps(message.value))
print(tweets)
While running the Producer,
python3 producer.py
we receive messages after running the consumer.py
From here you can do additional processing such as sentiment analysis using the Data.
Conclusion
To conclude, Kafka is a distributed publish-subscribe messaging system that maintains feeds of messages in partitioned and replicated topics. Its uses are as multiple as you can see here.
Also, we have created a Twitter stream divided into modules. The first module is for getting data from the Twitter API and putting it into Kafka Cluster and the second module is for reading the data from Kafka Cluster and doing processing separately. This allows us to be more flexible, getting no fault tolerance and helps process the data without worrying about the stream getting disconnected.
References: