
Sentiment Analysis Concept - Bitcoin Sentiment Analysis Using Python and Twitter


As human beings, we have to communicate with the other people with whom we live on this earth. For this purpose, languages have been invented so that we can easily share information, send messages but also share our sentiments which are detectable by our words.
With digitalization, many social networks were born. Companies are turning to the internet and the various social networks to receive information that users can give about a specific product, service or subject in order to understand the customers.
We have for example Twitter which is a social network where people give their opinions every second around the world using tweets. And, it is a vault of information that can be used.
Therefore, Sentiment Analysis also known as opinions mining is the understanding and extraction of feeling using Data based on the need of the research. AI can help us analyse the emotions of the general public and gather insightful information regarding the context.
In this article, we are going to talk about sentiment analysis using Twitter.
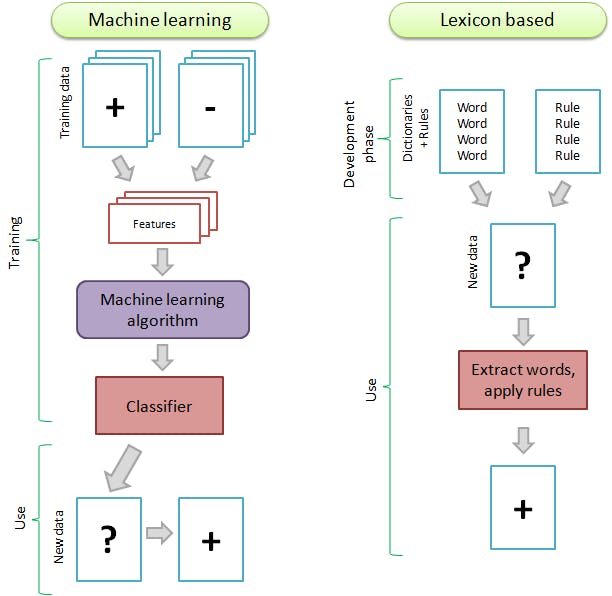
Approches of sentiments analysis
There are 2 general approaches to sentimental Analysis.
Rule/lexicon-based approach
Here the process is done in 3 main steps:
The tweet is divided into several words according to the categories (name, adverb, verb...) which are tag. We then get a list of tokens(list of words): This process is called Tokenization.
Each token is associated with the number of occurrences in the tweet. This forms what we call the bag of words.
Then, the token is compared to a database of words that are labelled as having positive or negative sentiment. These databases were created by researchers and contain a list of positive and negative sentiment words.
A tweet with more positive words than negative is scored as a positive. One with more negative words is scored as a negative, and if there were no positive/negative words or the same number, it is scored as neutral.
Automatic
With this approach, if we have a corpus of tweets that are labelled as positive or negative, we can create with a Machine Learning algorithm a classifier. We can then train a classifier on the tweets and, given a new tweet it would identify if is positive or negative.
Use case: Bitcoin Sentiment Analysis with Python and Twitter
For this use case, I used the Twitter API and the Python Librairie named Textblob
Textblob
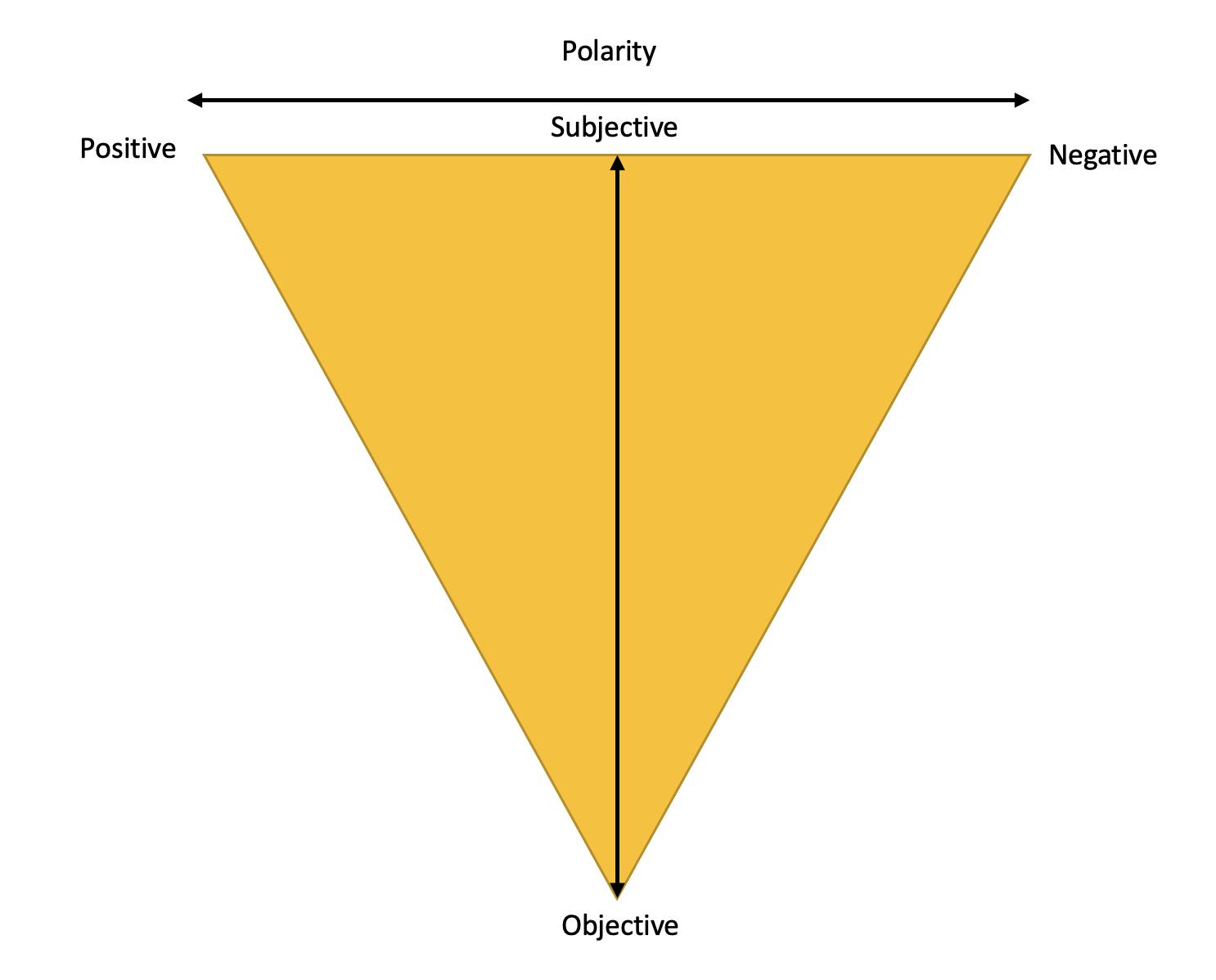
It is a simple python library that offers API access to different NLP tasks such as sentiment analysis, spelling correction, etc. With Textblob, Sentiment Analysis refers to the method to extract subjectivity and polarity from the text.
A sentence is said to be subjective if it contains non-factual information such as personal opinions, predictions and judgements.
A sentence is objective if it contains facts rather than opinions.
The polarity of a text is given by a decimal (float) value in the range of [-1,1]. It denotes the positivity of the tone of the given sentence.
Negative Sentiment: Polarity < 0; Neutral Sentiment: Polarity =0; Positive Sentiment: Polarity >0
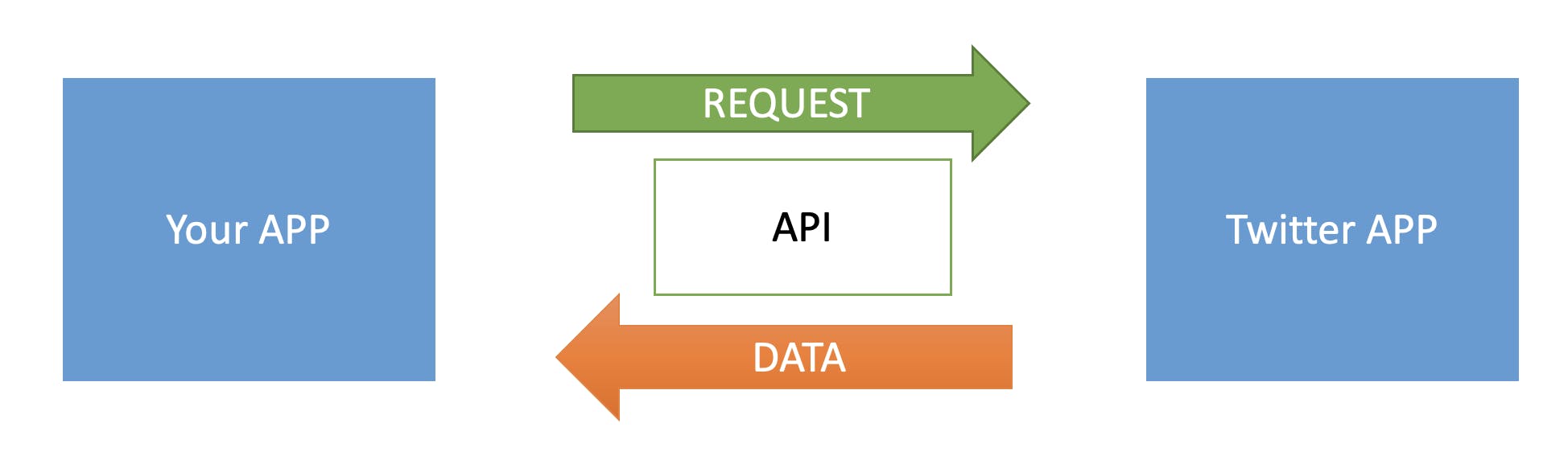
Twitter API
API stands for Application Programming Interface. With an API we can access the internal functionality of an Application. In our case, we want to access the Twitter API. I invite you to watch this video to determine how to connect to the Twitter API and get credentials.
Steps to apply Sentiment Analysis using TextBlob
I used Google Collab to run my code
Import libraries
# Import libraries
import tweepy
from textblob import TextBlob
import pandas as pd
import numpy as np
import re # regular expression
import matplotlib.pyplot as plt
Import Twitter API credentials
# upload file
from google.colab import files
files.upload()
Then connect to the API
# get the credentials
consumerKey = log["Key"][0]
consumerSecret = log["Key"][1]
accessToken = log["Key"][2]
accessTokenSecret = log["Key"][3]
# create the authentication object
authenticate = tweepy.OAuthHandler(consumerKey, consumerSecret)
# set the access token and the access token secret
authenticate.set_access_token(accessToken, accessTokenSecret)
# create the API object
api = tweepy.API(authenticate, wait_on_rate_limit=True)
Filter the tweets to only get tweets about bitcoin. For this example, we will take 2000 tweets in English that have been published since January 2018-11-01.
# Gather the 2000 tweets about Bitcoin and filter out any retweets 'RT'
search_term = '#bitcoin -filter:retweets'
# create a cursor object
tweets = tweepy.Cursor(api.search, q=search_term, lang='en', since='2018-11-01', tweet_mode='extended').items(2000)
# tweepy.Cursor(api.search, q, tweet_mode='extended').items(tweetNumber)
# store the tweets in a variable and get the full text
all_tweets = [tweet.full_text for tweet in tweets]
Clean the tweets by removing the '#', hyperlinks...
# Create a function to clean the tweets
def cleanTwt(twt):
twt = re.sub('#bitcoin', 'bitcoin', twt) # Removes the '#' from bitcoin
twt = re.sub('#Bitcoin', 'Bitcoin', twt) # Removes the '#' from Bitcoin
twt = re.sub('#[A-Za-z0-9]+', '', twt) # Removes any strings with a '#'
twt = re.sub('\\n', '', twt) # removes the '\n' string
twt = re.sub('https?:\/\/\S+', '', twt) # Removes any hyperlinks
return twt
# Clean the Tweets
df['Cleaned_Tweets'] = df['Tweets'].apply(cleanTwt)
Use TextBlob to determine the polarity and subjectivity of each tweet as well as the sentiment
# Create a function to get the subjectifvity
def getSubjectivity(twt):
return TextBlob(twt).sentiment.subjectivity
# Create a function to get the polarity
def getPolarity(twt):
return TextBlob(twt).sentiment.polarity
#Create two new columns called 'subjectivity' and 'Polarity'
df['Subjectivity'] = df['Cleaned_Tweets'].apply(getSubjectivity)
df['Polarity'] = df['Cleaned_Tweets'].apply(getPolarity)
#Create a function to get the sentiment text
def getSentiment(score):
if score < 0:
return 'Negative'
elif score ==0:
return 'Neutral'
else:
return 'Positive'
#Create a column to score the text sentiment
df['Sentiment'] = df['Polarity'].apply(getSentiment)
Well done you have created a Bitcoin Sentiment Analysis. Let's use graphics to visualize.
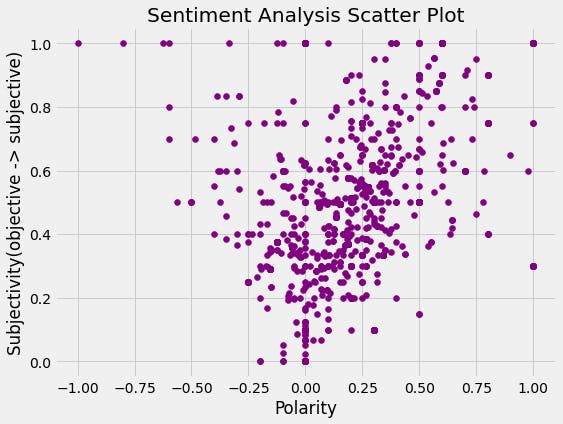
#Create a scatter plot to show the subjectivity and polarity
plt.figure(figsize=(8,6))
for i in range(0, df.shape[0]):
plt.scatter(df['Polarity'][i], df['Subjectivity'][i], color='Purple')
plt.title('Sentiment Analysis Scatter Plot')
plt.xlabel('Polarity')
plt.ylabel('Subjectivity(objective -> subjective)')
plt.show()
#Create a bar chart to show the count of Positive, Neutral and Negative sentiments
df['Sentiment'].value_counts().plot(kind='bar')
plt.title('Sentiment Analysis Bar Plot')
plt.xlabel('Sentiment')
plt.ylabel('Number of tweets')
plt.show()
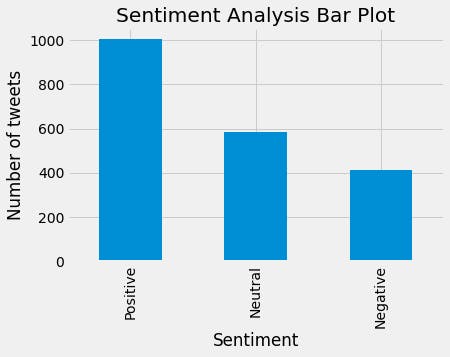
In conclusion, we note that out of the 2000 tweets, the vast majority are positive and that we have very few negative tweets. We can therefore understand that we can analyse the feelings through the tweets with the lexicon-based method. To go further, we will later use other methods of sentiment analysis before concluding definitively on the most effective and efficient method.
The full code is available on my GitHub page: : github.com/g-lorena/bitcoin_sentiment_analy..
Conclusion
Sentiment analysis is the process to understand and extracting feelings from Data. It can be rule-based, matching words with sentiment scores from Lexicon or automated, where a trained pattern matching algorithm will predict the sentiment of a word. AN API let us access an app's functionality using code. We can build a sentiment analysis in a few lines using the Twitter API.
References