Sentiment analysis on streaming Twitter data using Kafka, Spark Structured Streaming & Python (Part 2)




Photo by Alexander Shatov on Unsplash
A friend told me one day that, a problem we face at x time is an assembly of small problems not resolved previously and that we aren't aware of.
I decided weeks ago to learn how to do sentiment analysis on streaming Twitter Data, but to do the entire project it was necessary to understand the architectural concept and walk step by step. I divided the process into multiple parts. I hope you will understand the overview throw every component, just view the component as a lego piece.
Part 1:
Sentiment analysis: This is a kind of Hello word for big data analysis. I wrote an article about the methodology. My goal was to connect to Twitter using his API and get several tweets about a particular topic. The topic I choose was Bitcoin. The project is also available on my Github.
Part 2:
After working on a specific quantity of Data as shown in the first part, I had to start building an architecture for real-time analysis. So, Understanding the key concept about Kafka,Apache Structured Streaming was important as the language to choose.
Goal
The goal is to do real-time sentiment analysis and store the result in MongoDB. The first part is available here. Now let's dive into the process.
Python packages:
TextBlob to do simple sentiment analysis on tweets (demo purpose only).
Data Processing Engine:
Spark: we will spark to process the Streaming
Storage
MongoDB: Here will we use MongoDB as the output sink.
Now, let's jump into it.
1. Data Ingestion
- Create a Kafka producer. The goal is to connect to Twitter API and get tweets about a particular topic.
import tweepy
from kafka import KafkaProducer
import logging
"""API ACCESS KEYS"""
consumerKey = "XXXX"
consumerSecret = "XXXX"
accessToken = "XXXX"
accessTokenSecret = "XXXX"
producer = KafkaProducer(bootstrap_servers='localhost:9092')
search_term = 'Bitcoin'
topic_name = 'twitter'
def twitterAuth():
# create the authentication object
authenticate = tweepy.OAuthHandler(consumerKey, consumerSecret)
# set the access token and the access token secret
authenticate.set_access_token(accessToken, accessTokenSecret)
# create the API object
api = tweepy.API(authenticate, wait_on_rate_limit=True)
return api
class TweetListener(tweepy.Stream):
def on_data(self, raw_data):
logging.info(raw_data)
producer.send(topic_name, value=raw_data)
return True
def on_error(self, status_code):
if status_code == 420:
# returning False in on_data disconnects the stream
return False
def start_streaming_tweets(self, search_term):
self.filter(track=search_term, stall_warnings=True, languages=["en"])
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
twitter_stream = TweetListener(consumerKey, consumerSecret, accessToken, accessTokenSecret)
twitter_stream.start_streaming_tweets(search_term)
- Create a Kafka consumer: send the information collected to the Kafka consumer.
from kafka import KafkaConsumer
import json
topic_name = 'twitter'
consumer = KafkaConsumer(
topic_name,
bootstrap_servers=['localhost:9092'],
auto_offset_reset='latest',
enable_auto_commit=True,
auto_commit_interval_ms=5000,
fetch_max_bytes=128,
max_poll_records=100,
value_deserializer=lambda x: json.loads(x.decode('utf-8')))
for message in consumer:
tweets = json.loads(json.dumps(message.value))
print(tweets)
2. The Streaming Pipeline
This will be done with Spark.
- First import the libraries:
from pyspark.sql import functions as F
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql.types import StringType, StructType, StructField, FloatType
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col, udf
from pyspark.ml.feature import RegexTokenizer
import re
from textblob import TextBlob
- Create Spark session and start reading stream which came from Kafka. This implies that the connection with Kafka has to be done.
spark = SparkSession \
.builder \
.appName("TwitterSentimentAnalysis") \
.config("spark.jars.packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2") \
.getOrCreate()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "twitter") \
.load()
Now do some transformation.
Here we just get the "text". As the data is coming from Kafka, this data is in a JSON form with multiple information such as the created date of the tweet, the username… And, "text" is the one that has the tweet text.
mySchema = StructType([StructField("text", StringType(), True)])
# Get only the "text" from the information we receive from Kafka. The text is the tweet produce by a user
values = df.select(from_json(df.value.cast("string"), mySchema).alias("tweet"))
Clean Data
The cleaning process is to remove links, users, punctuation, numbers and hashtags.
def cleanTweet(tweet: str) -> str:
tweet = re.sub(r'http\S+', '', str(tweet))
tweet = re.sub(r'bit.ly/\S+', '', str(tweet))
tweet = tweet.strip('[link]')
# remove users
tweet = re.sub('(RT\s@[A-Za-z]+[A-Za-z0-9-_]+)', '', str(tweet))
tweet = re.sub('(@[A-Za-z]+[A-Za-z0-9-_]+)', '', str(tweet))
# remove puntuation
my_punctuation = '!"$%&\'()*+,-./:;<=>?[\\]^_`{|}~•@â'
tweet = re.sub('[' + my_punctuation + ']+', ' ', str(tweet))
# remove number
tweet = re.sub('([0-9]+)', '', str(tweet))
# remove hashtag
tweet = re.sub('(#[A-Za-z]+[A-Za-z0-9-_]+)', '', str(tweet))
return tweet
Here, we apply the clean function on UDF (User Defined Function) and then create a new column with the clean data.
df1 = values.select("tweet.*")
clean_tweets = F.udf(cleanTweet, StringType())
raw_tweets = df1.withColumn('processed_text', clean_tweets(col("text")))
3. Sentiment analysis
First get the subjectivity, polarity and sentiment :
# Create a function to get the subjectifvity
def getSubjectivity(tweet: str) -> float:
return TextBlob(tweet).sentiment.subjectivity
# Create a function to get the polarity
def getPolarity(tweet: str) -> float:
return TextBlob(tweet).sentiment.polarity
def getSentiment(polarityValue: int) -> str:
if polarityValue < 0:
return 'Negative'
elif polarityValue == 0:
return 'Neutral'
else:
return 'Positive'
Apply it to tweet:
subjectivity = F.udf(getSubjectivity, FloatType())
polarity = F.udf(getPolarity, FloatType())
sentiment = F.udf(getSentiment, StringType())
subjectivity_tweets = raw_tweets.withColumn('subjectivity', subjectivity(col("processed_text")))
polarity_tweets = subjectivity_tweets.withColumn("polarity", polarity(col("processed_text")))
sentiment_tweets = polarity_tweets.withColumn("sentiment", sentiment(col("polarity")))
When applying it into the console, we see something like that:
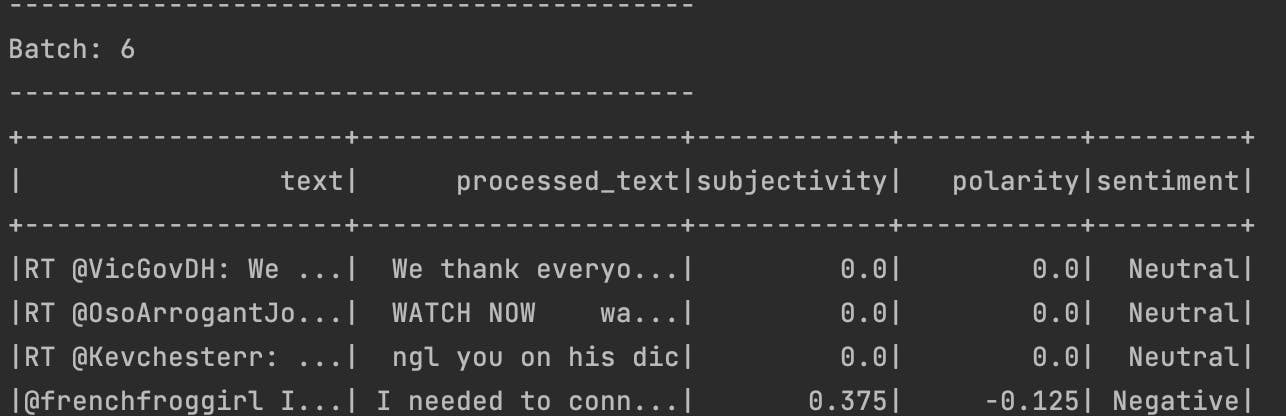
4. Store data frame into MongoDB Atlas
Here, I have to reveal that it wasn't the easier part as I am not familiar with MongoDB Atlas and didn't know how to connect spark to this output sink. I just had to store my output in MongoDB Atlas which is the best way to deploy, run and scale MongoDB in the cloud. The process is as follow:
- Go to the website and create an account
- Create a Cluster
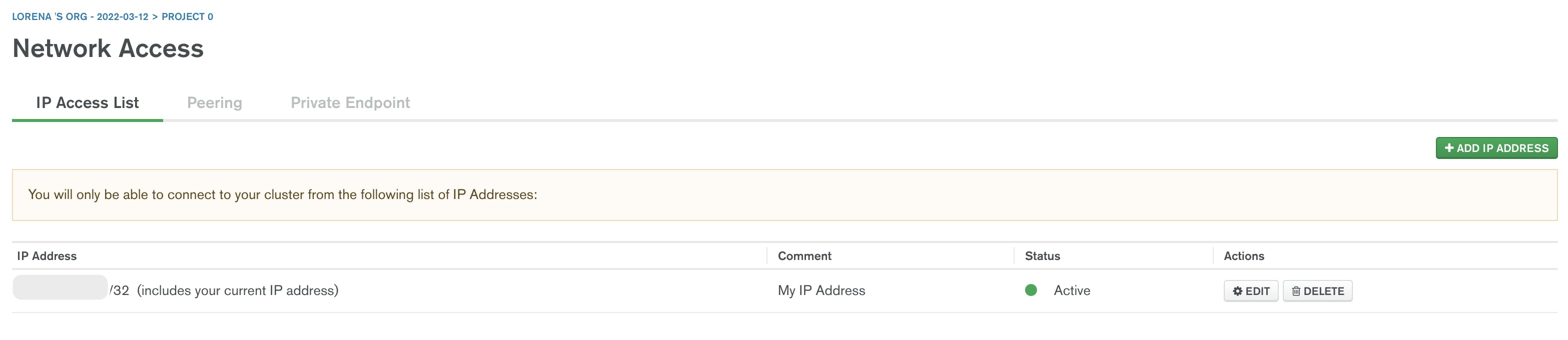
- Give access to your IP address to have permission to connect to your cluster as shown in the image above
- Create a database and a collection
Congratulations you did the first part of the work. Now, let's connect our spark to MongoDB. To do this:
- Go to the overview page
- Then "connect"

- Choose your Driver, the version and copy the output. Make sure to modify the password, collection and database name. You will get something like this:
mongodb+srv://Lorena:<password>@cluster0.9psdq.mongodb.net/myFirstDatabaseretryWrites=true&w=majority
After this, add this to the spark session and update the spark session configuration:
spark = SparkSession \
.builder \
.appName("TwitterSentimentAnalysis") \
.config("spark.mongodb.input.uri",
"mongodb+srv://<Username>:<Password>@cluster0.9psdq.mongodb.net/<database_name>.<database_collection>"
"?retryWrites=true&w=majority") \
.config("spark.mongodb.output.uri",
"mongodb+srv://<Username>:<Password>@cluster0.9psdq.mongodb.net/<database_name>.<database_collection>"
"?retryWrites=true&w=majority") \
.config("spark.jars.packages", "org.mongodb.spark:mongo-spark-connector_2.12:3.0.1") \
.config("spark.jars.packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2") \
.getOrCreate()
- Create a function to add a row in mongo and save:
def write_row_in_mongo(df, epoch_id):
mongoURL = "mongodb+srv://Lorena:<Password>@cluster0.9psdq.mongodb.net/<database>.<collection>" \
"?retryWrites=true&w=majority "
df.write.format("mongo").mode("append").option("uri", mongoURL).save()
pass
- And, start writing stream in MongoDB
query = sentiment_tweets.writeStream.queryName("test_tweets") \
.foreachBatch(write_row_in_mongo).start()
query.awaitTermination()
Well done, now we can see that the data is stored in the database.
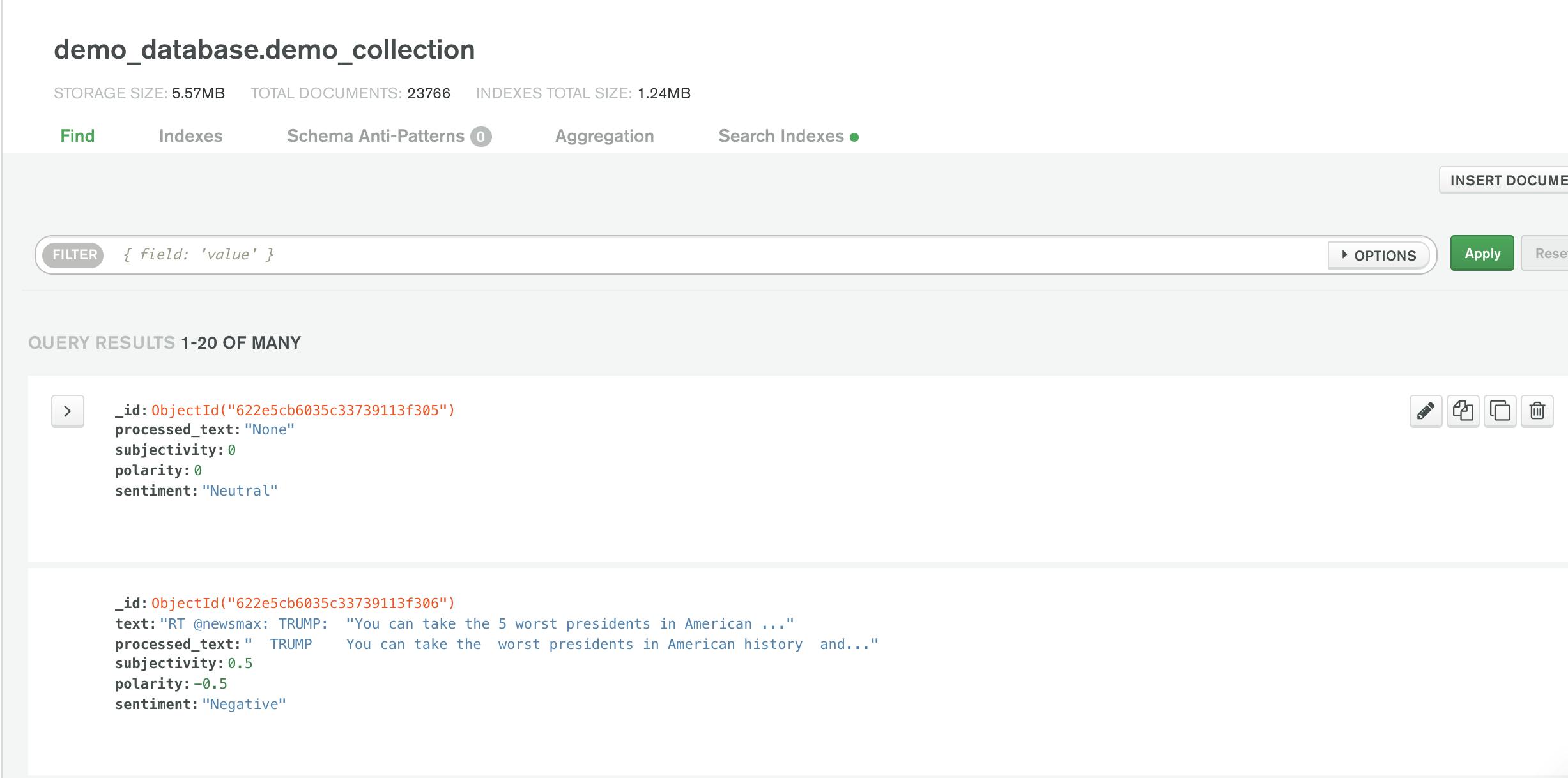
Conclusion
To conclude, the goal of the second part was to collect the cleaned tweets and send them into an output sink. The one I choose here is MongoDB. The objective has been reached and I will improve it and I will continue with the other parts during the next weeks. The project is available on my GitHub.
I hope this information was helpful and interesting, if you have any questions, or you just want to say hi, I'm happy to connect and respond to any questions you may have about my blogs! Feel free to visit my website for more!