


Imagine you could go on websites and extract automatically information you want about a particular topic: this is Web Scraping. Web Scraping help to extract non-structured data on websites. Understanding this method requires having prerequisites on the fundamentals of a website. A website has many web pages, and every page is an HTML file that contains information.
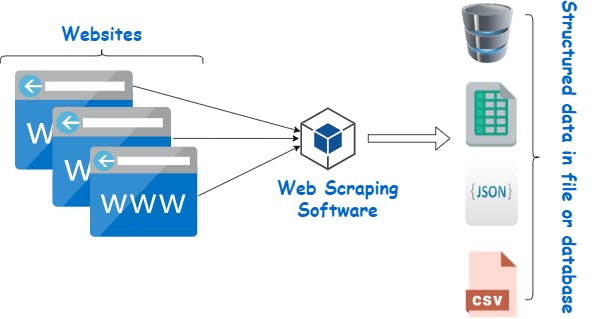
There is another technique called crawling. And in comparison to Web Scraping, it extracts all the information available on the website, including texts, hyperlinks, contact, and keywords.
Why you should scrape real estate data
Real estate is a growing industry, and it could be important for real estate agents to understand the different factors that can influence the price of a real estate property. We can cross real estate data available on websites with other helpful information to know if the price of a property will increase or fall or if there is considerable demand in a particular neighbourhood. But also, at a superficial level, we can analyze those data and, for example, find cities or areas where houses are expensive and many other axes of analysis.
After extracting data from websites, we can find the answer to all these questions. And for this, we all know that Web scraping is a powerful engine for data extraction.
This article will extract data from a french website where real estate properties are presented for rent or buy. The type of data that we will extract from the different web pages are:
- Property type
- Sale price
- Address
- Size
- rooms
- number of pieces
- real estate agency
How Web Scraping can be valued
Web Scraping can be valued by everyone interested in Real Estate and has some notion of computer science.
If you are an investor and want to make a deal on real estate, it is essential to know when to buy or know the best rental price for your property. You need to know when the price will pup-up or will be down. But also to know when to buy a property. To be a profitable investor in real estate, we can apply web scraping, which can be a good solution.
This article will search home with two pieces in Nice (France). We will create our web scraper from scratch and extract content from web pages of the website seloger.com.
Building a web scraper to extract real estate data
The libraries used:
I use different libraries for this project:
- BeautifulSoup: This library makes it easy to scrape information from web pages and analyze HTML documents.
- Pandas: This library helps with data manipulation, and we will store the extracted data in a structured format.
- Requests: It supports HTTP requests.
import requests
import pandas as pd
from bs4 import BeautifulSoup
To install them within the project is quite simple. Just use this command line in the project's terminal:
pip install requests beautifulsoup4 pandas
Get the pages
As we mentioned, the data are available on seloger.com, and we need to get the URL of the page. I recommend using chrome while doing web scraping.
url = "https://www.seloger.com/list.htm?projects=2,5&types=2,1&natures=1,2,4&places=[{%22inseeCodes%22:[60088]}]&rooms=2&mandatorycommodities=0&enterprise=0&qsVersion=1.0&LISTING-LISTpg=1"
It is essential to understand the URL structure before jumping into coding because the URL will give us information about how to get the other pages.
For example, after comparison of the URL of the first and second pages, I noticed that only the value of "LISTING-LISTpg" changed. When we go to page 2, the URL is :
url = "https://www.seloger.com/list.htm?projects=2,5&types=2,1&natures=1,2,4&places=[{%22inseeCodes%22:[60088]}]&rooms=2&mandatorycommodities=0&enterprise=0&qsVersion=1.0&LISTING-LISTpg=2"
This information will help us iterate on pages. In this article, we will focus only on the first page.
Now, we test the querying on this page using the URL. By running this,
response = requests.get(url)
response
The value of the response can give us information about the query. Whether it is OK, Forbidden, or has an error.
Some websites can block when they receive python code. It is essential to know how to get out of this issue to solve this problem. I recommend reading the article below that I found interesting: codementor.io/@scrapingdog/10-tips-to-avoid...
What is a User-agent and how can this solve the issue?
A User-agent is a browser in a web context, and the purpose of using it is to fake the usage of a browser on the computer. With this method, the website that we try to attend using a user agent wouldn't block because the user agent is considered a person using the browser.
To do this, run the code below.
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
response = requests.get(url, headers=headers)
We have then access to the entire page and its information.
Inspect the web page
This step is essential for the success of this project. To do this, go on the web page and right-click the go-to Inspect. We get something like this:

In the right section of the image, we see tags that have the information we need. We have to understand how it functioned deeply. As I said earlier, having fundamentals in web development could be good.
Collecting information
I decided to get data related to :
- Price
- Type of property
- numbers of pieces
- numbers of rooms
- size
- Address
- real estate agency

When inspecting the web page, we see, for example, that "div" that has information on a particular property has the same class "value". The method is to dig deep using the mouse.
We obtain this simple code for scraping:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
list_all_ads = []
for element in soup.find_all('div', attrs={'class': 'ListContent-sc-1viyr2k-0 klbvnS '
'classified__ClassifiedContainer-sc-1wmlctl-0 dlUdTD '
'Card__CardContainer-sc-7insep-5 kLpWdA'}):
price = element.find('div', attrs={'data-test': 'sl.price-label'}).text # => price.text return the price value
agency_link = element.find_all('div', {'class': 'Contact__ContentContainer-sc-3d01ca-2 cKwmCO'})
for agency in agency_link:
agency_name = agency.a.text
agency_name_value = agency_name
type = element.find('div', attrs={'data-test': 'sl.title'}).text
address = element.find('div', attrs={'data-test': 'sl.address'}).text
ul_tagsLine_0 = element.find('ul', attrs={'data-test': 'sl.tagsLine_0'})
list_ul_tagsLine_0 = []
for li in ul_tagsLine_0.find_all("li"):
list_ul_tagsLine_0.append(li.text)
numbers_of_pieces, rooms, size = getLiValue(list_ul_tagsLine_0)
# print('\n')
list_all_ads.append({"price": price, "agency_name": agency_name_value, "type":type, "address":address, "numbers_of_pieces":numbers_of_pieces, "rooms":rooms, "size":size})
Great, now that we have data, we can store them in a Dataframe.
df_seloger = pd.DataFrame(list_all_ads)
df_seloger.to_csv('listings.csv', index=False, encoding='utf-8')
Conclusion
This article shows that it is possible to analyze web pages and store information about a particular subject. This article was an introduction to web scraping with python and BeautifulSoup.
This article shows that I plan to cover web scraping to multiple pages, not just one. And store them in an appropriate Data Storage.
I hope this information was helpful and exciting. If you have any questions or want to say hi, I'm happy to connect and respond to your questions about my blogs! Feel free to visit my website for more!
REFERENCES: